Sampling and design of experiment
The journey starts with a sampling. Sampling provides a clear and concise approach to obtaining the data necessary for optimal AI model training.
Following the step-by-step Sampling process allows you to obtain an optimal set of data that best represents the full “possibility space.”
Open one of your projects in Proteus and go to the Sampling list view.
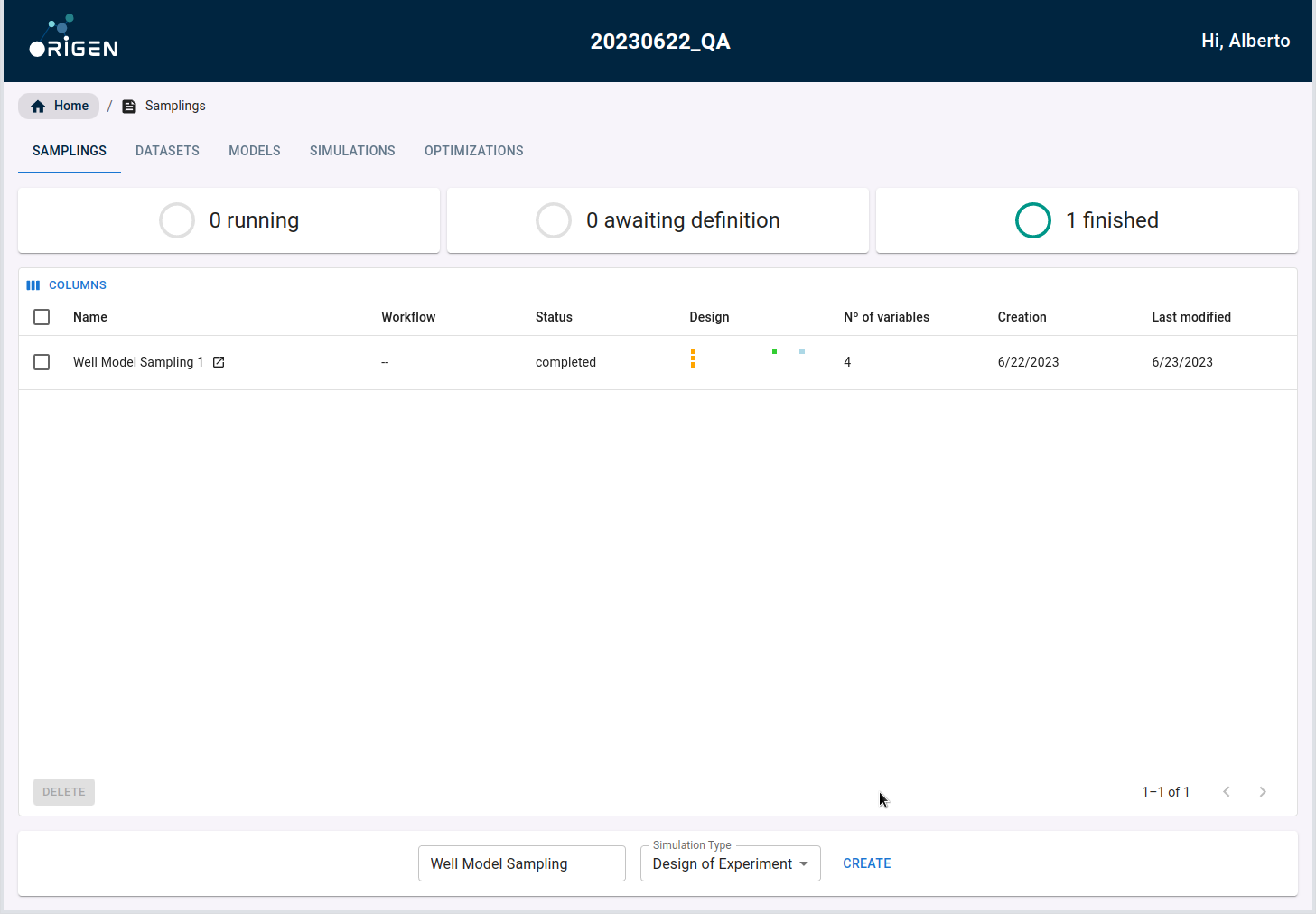
Once there, create a sampling by providing a name in the central bottom part of the page. Click the "Create" button to proceed.
Currently, OriGen now only offers the Design of Experiments (DoE) methodology for sampling as is outlined in the subsequent steps.
After the DoE sampling has been created, you will be directed to a step-by-step walkthrough.
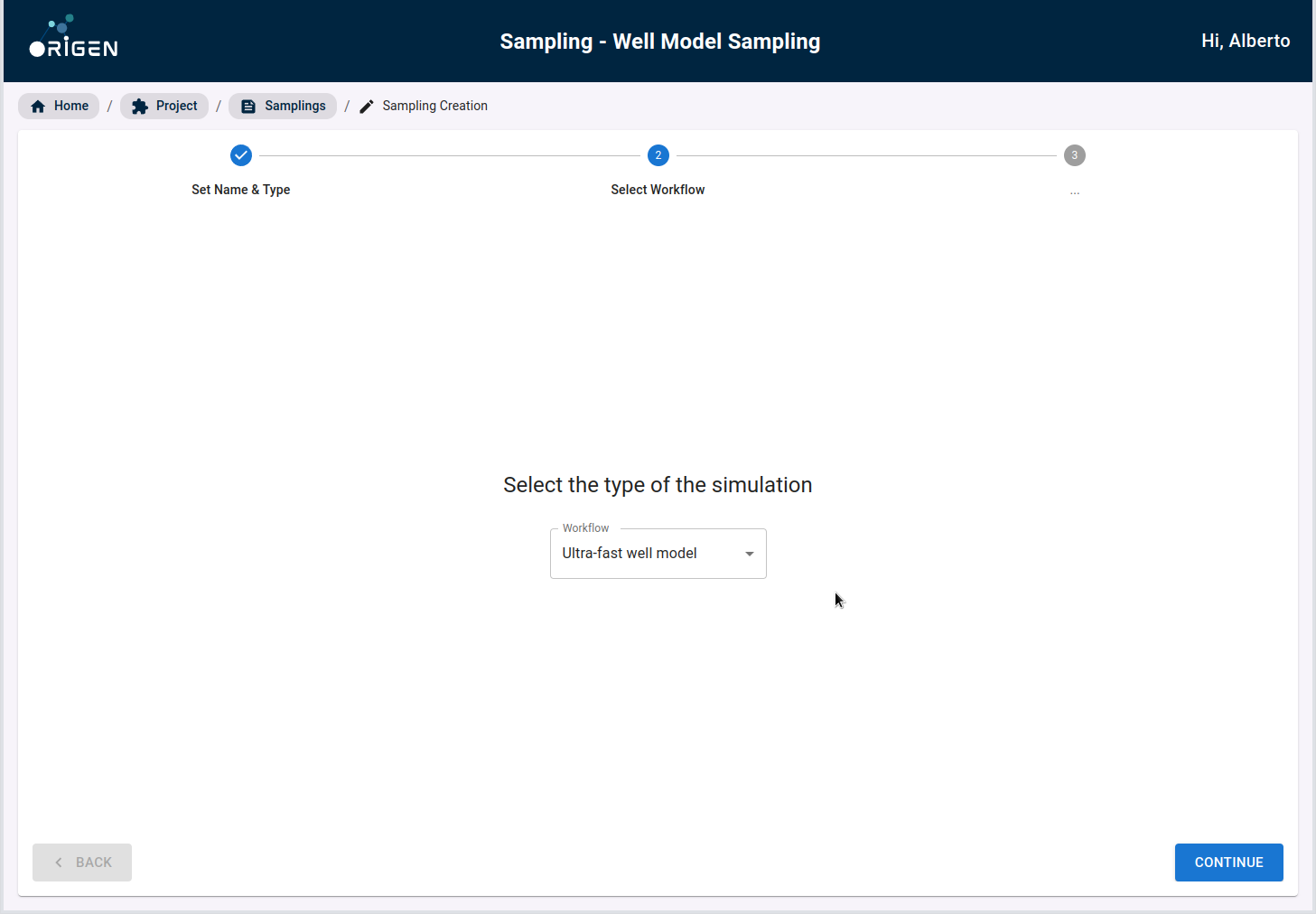
In the first view, you will be able to select the type of sampling to be generated. Please select the "UF Well Model" option.
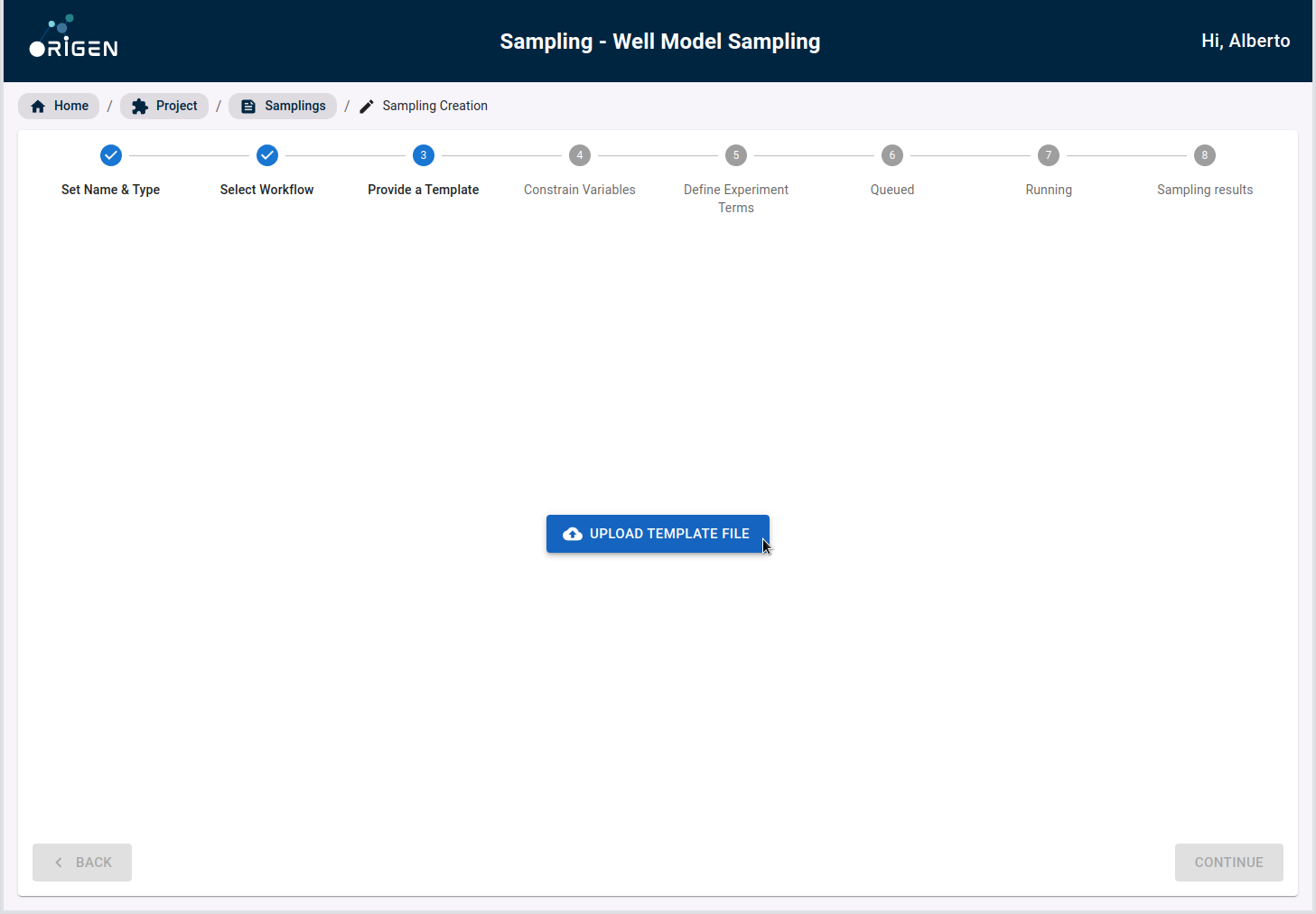
The next step for the Sampling walkthrough will be to modify a template file with the desired variables the reservoir engineer wants to change. A sample template is included for users to download and review. The .DATA file reservoir engineers commonly work with is modified to allow for specific variables to be named.
Once these variables are named, the rest of the process will allow you to provide a distribution of each given variable based on their own judgment. A default distribution for each variable type will also be recommended for users unfamiliar with the subject.
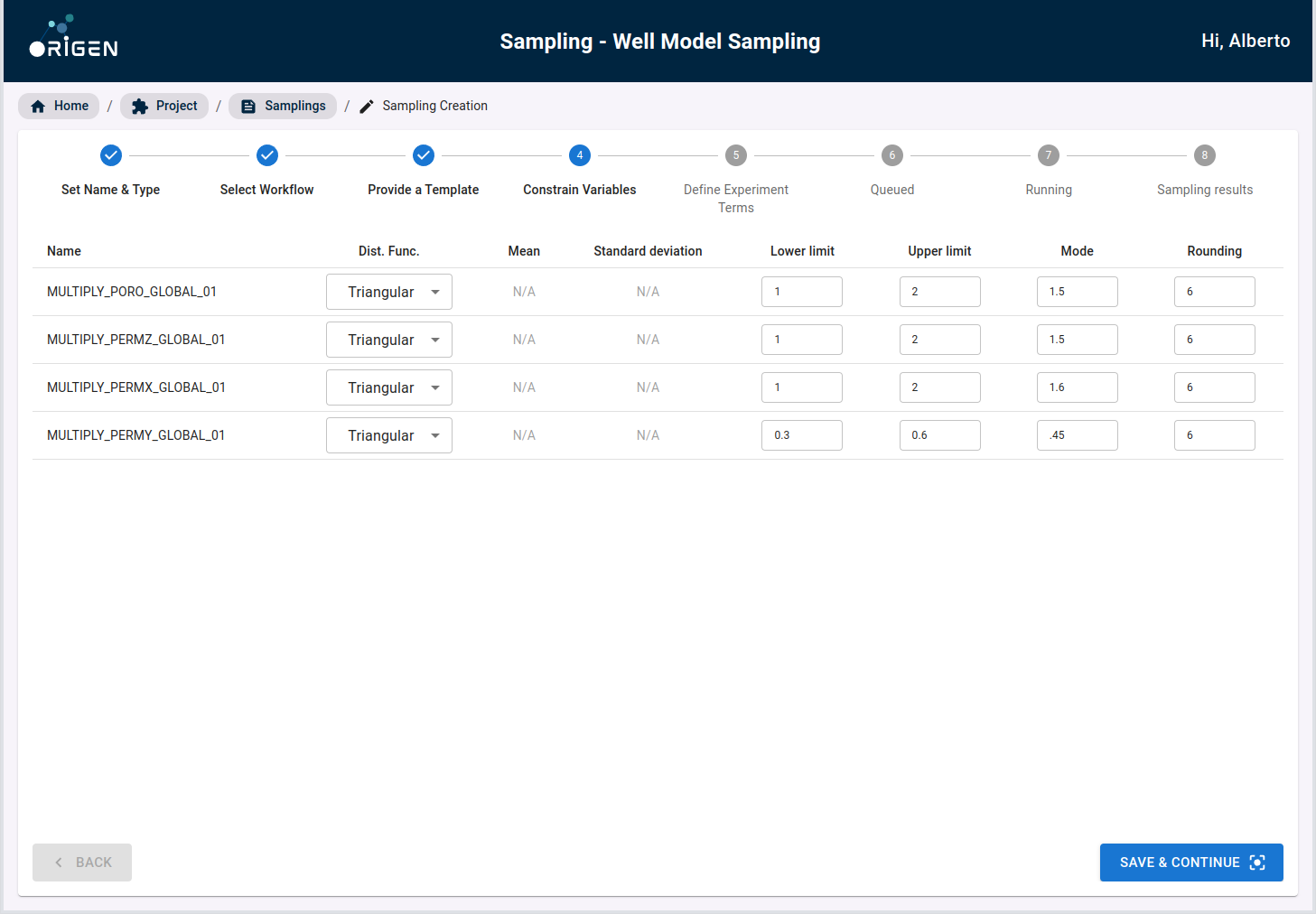
Once the variables have been constrained, you will then be prompted to create the training-validation-testing split. This is a core practice in machine learning that most users with machine learning experience should have encountered before. At a high level, the AI model is trained on the “training set” and then subsequently, the trained model is then evaluated on the never before seen “validation” and “testing” data in order to determine the performance (fit) of the trained model. Default split values are provided for users unfamiliar with the subject.
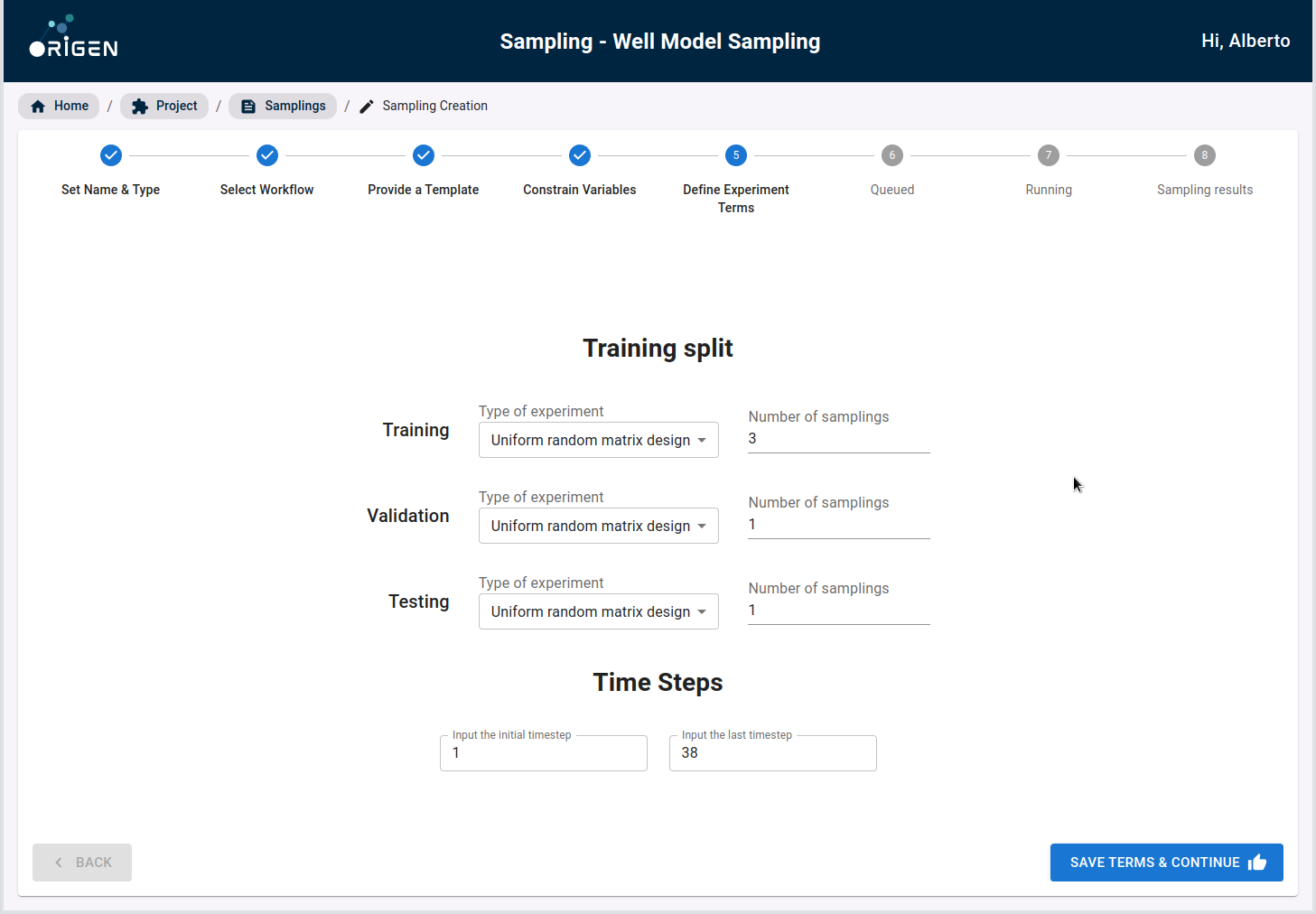
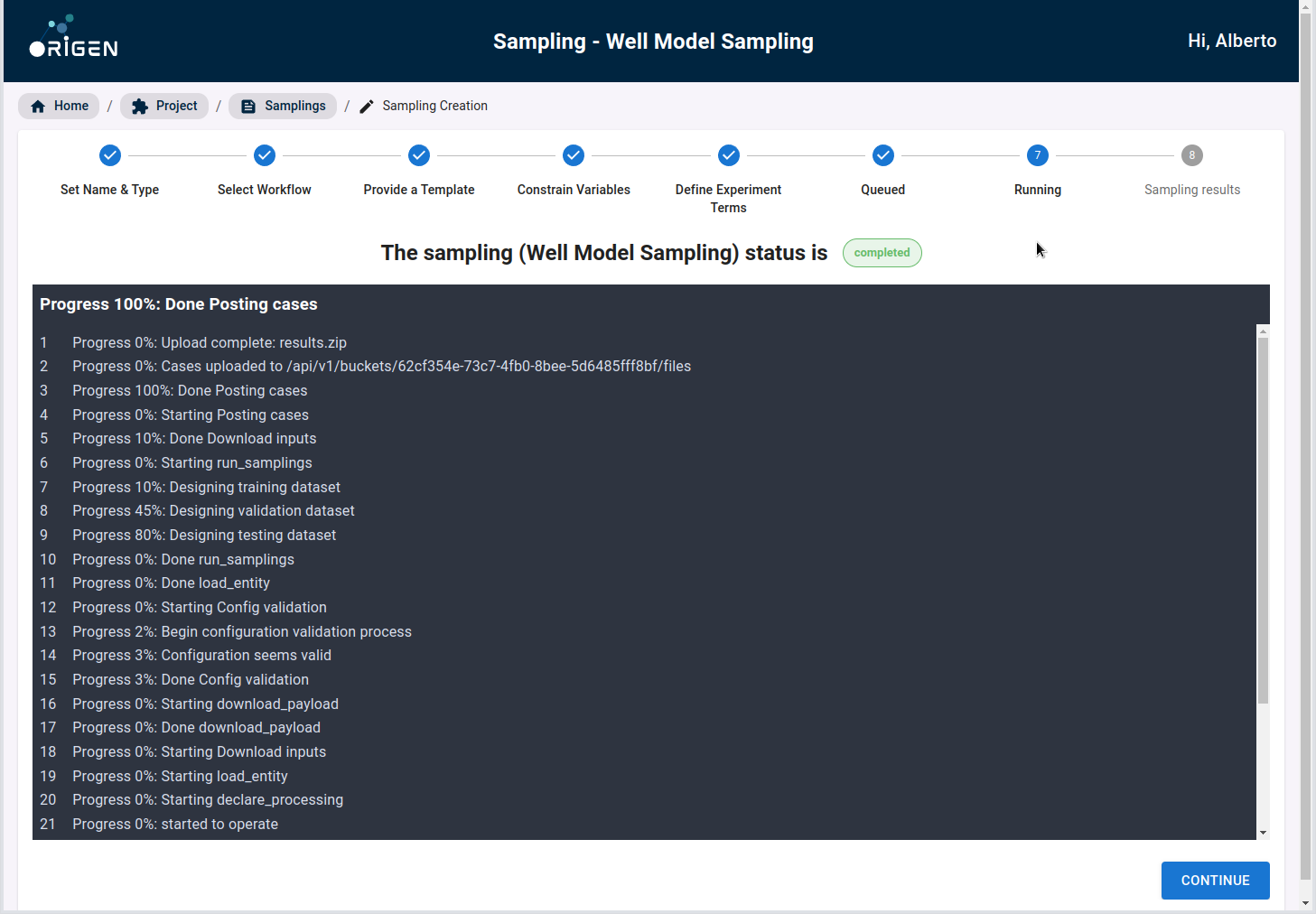
In the following screen, you can see a summary of the data configured before being launched.
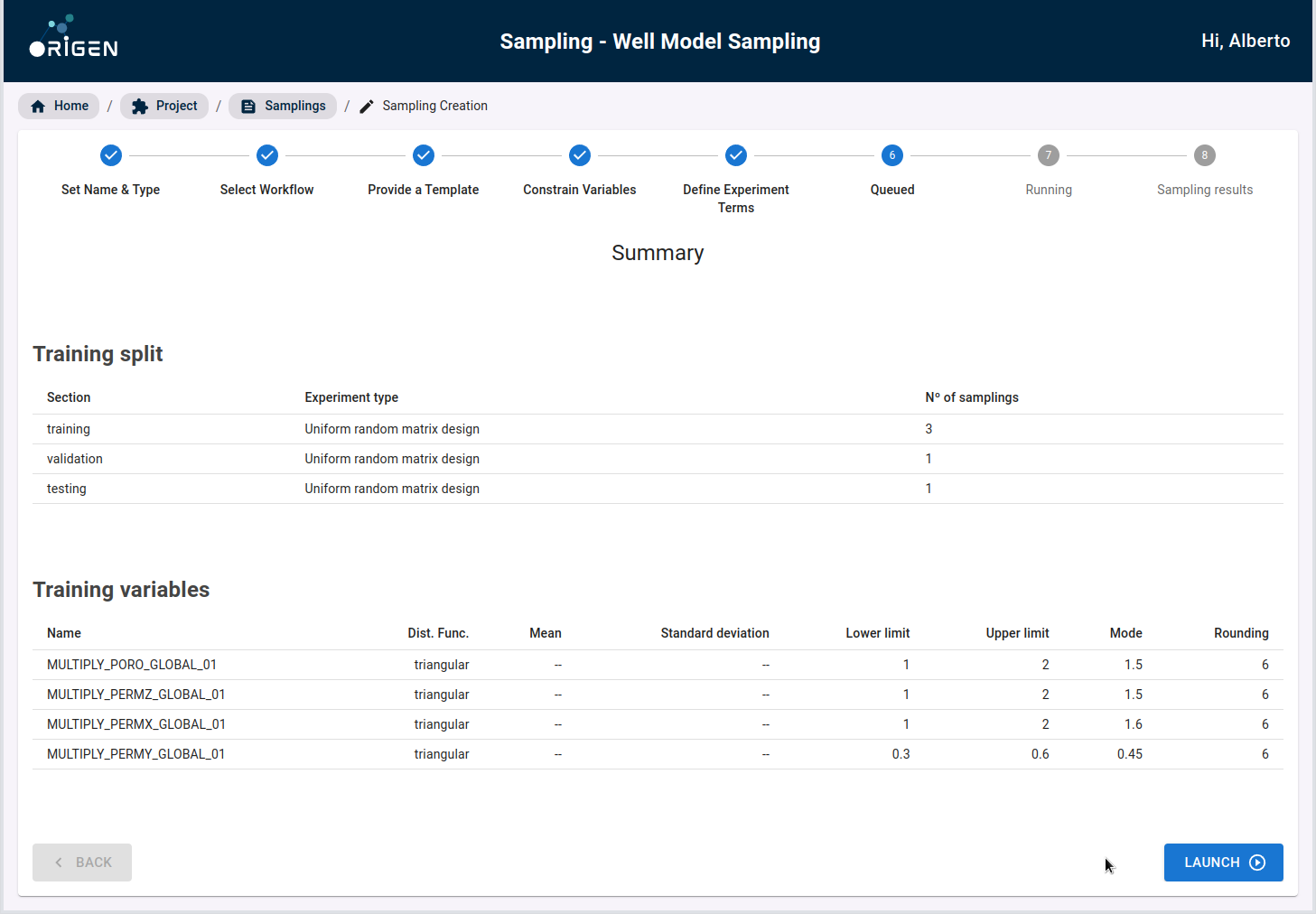
Once the model split has been confirmed, you can then submit the Sampling for processing. For this step, OriGen takes the variables, their distributions, and the training validation testing split into consideration, and generates a complete set of Eclipse cases.
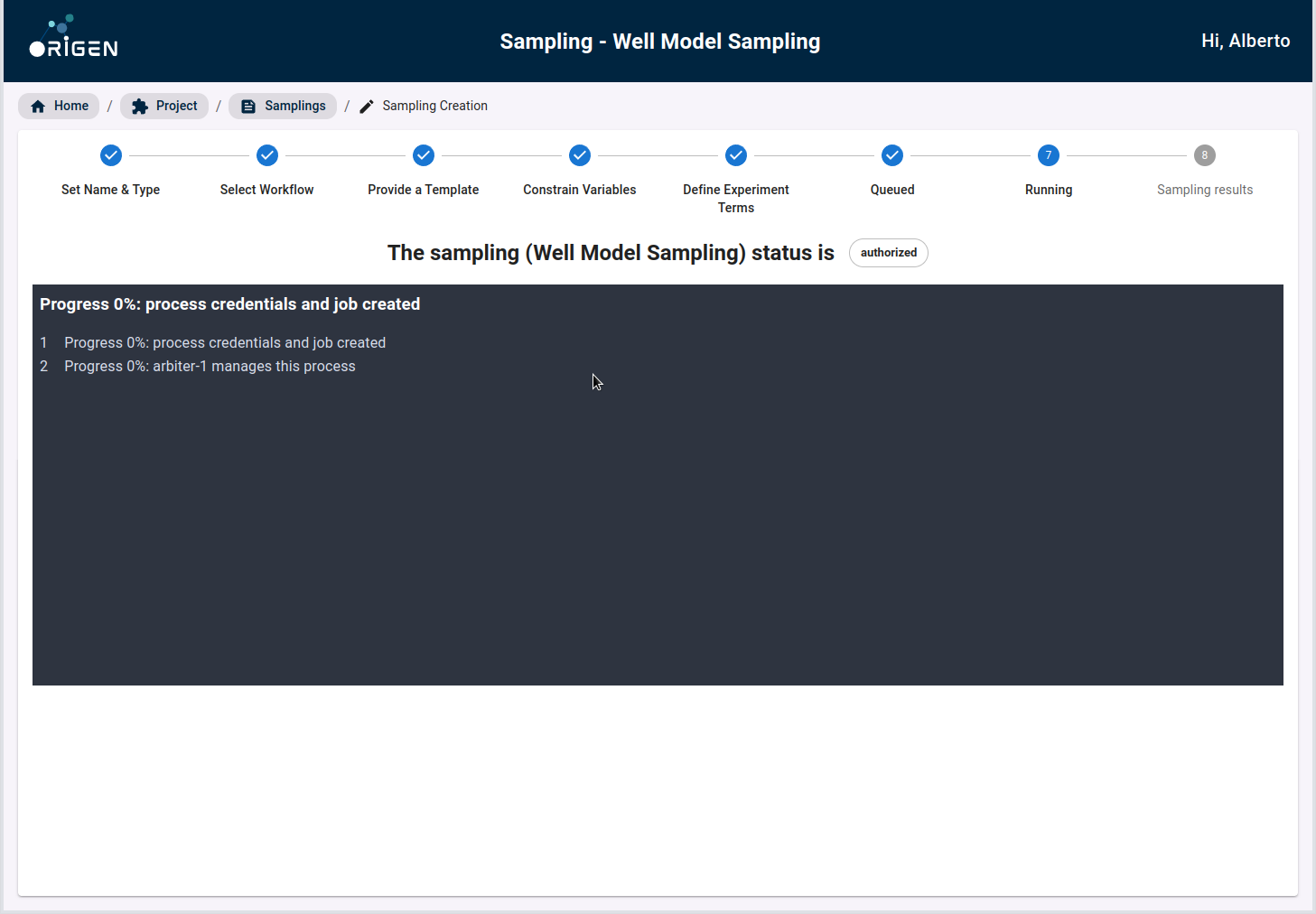
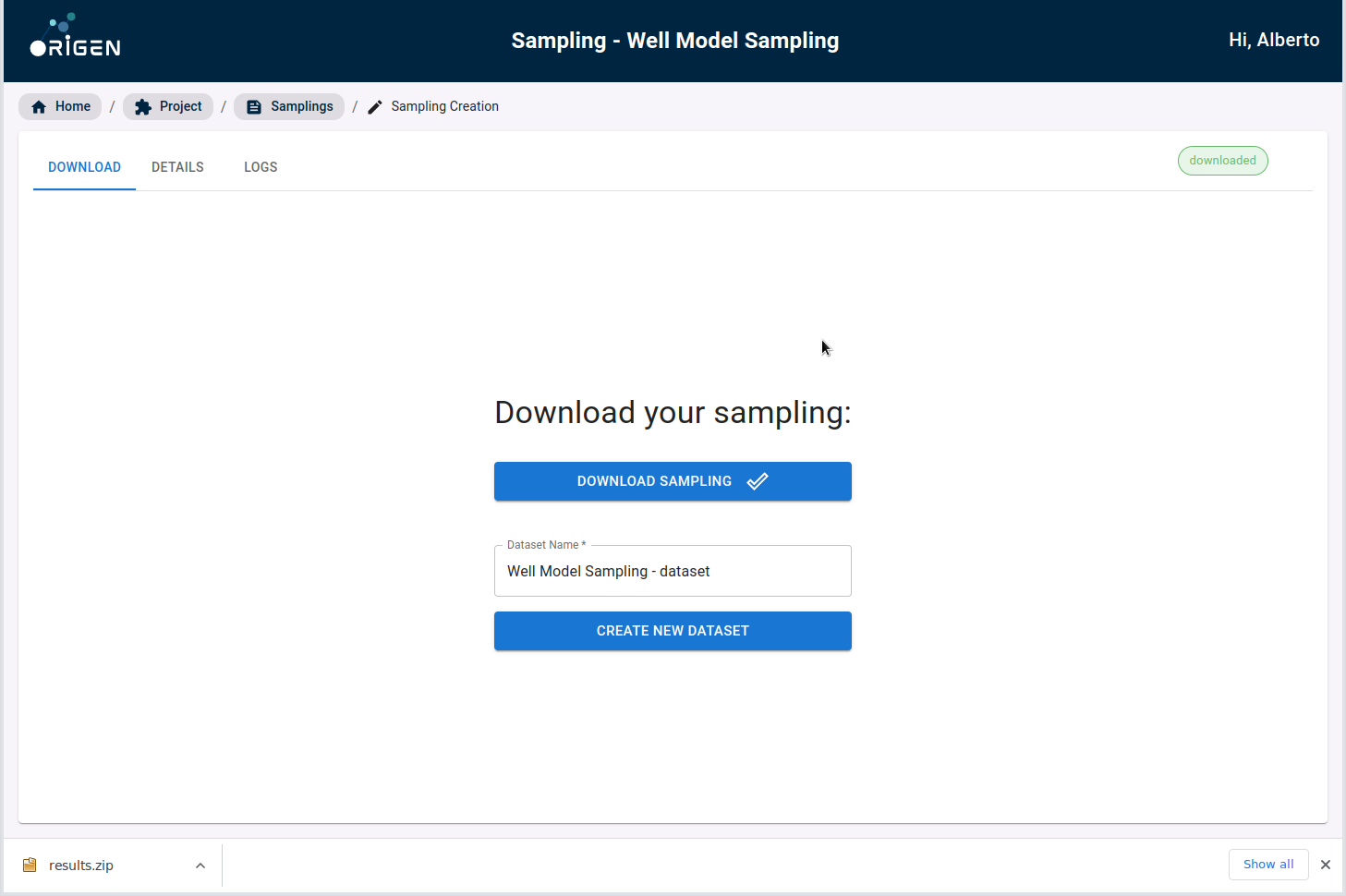
This set of Eclipse cases can then be downloaded by you. Once downloaded, you must run these cases in their conventional reservoir simulator just as they would do in their original reservoir simulator workflow.
Note You need to click on Download sampling button to activate the create dataset button
You can also check in the other tabs, details of the sampling configuration, as well as the log records.
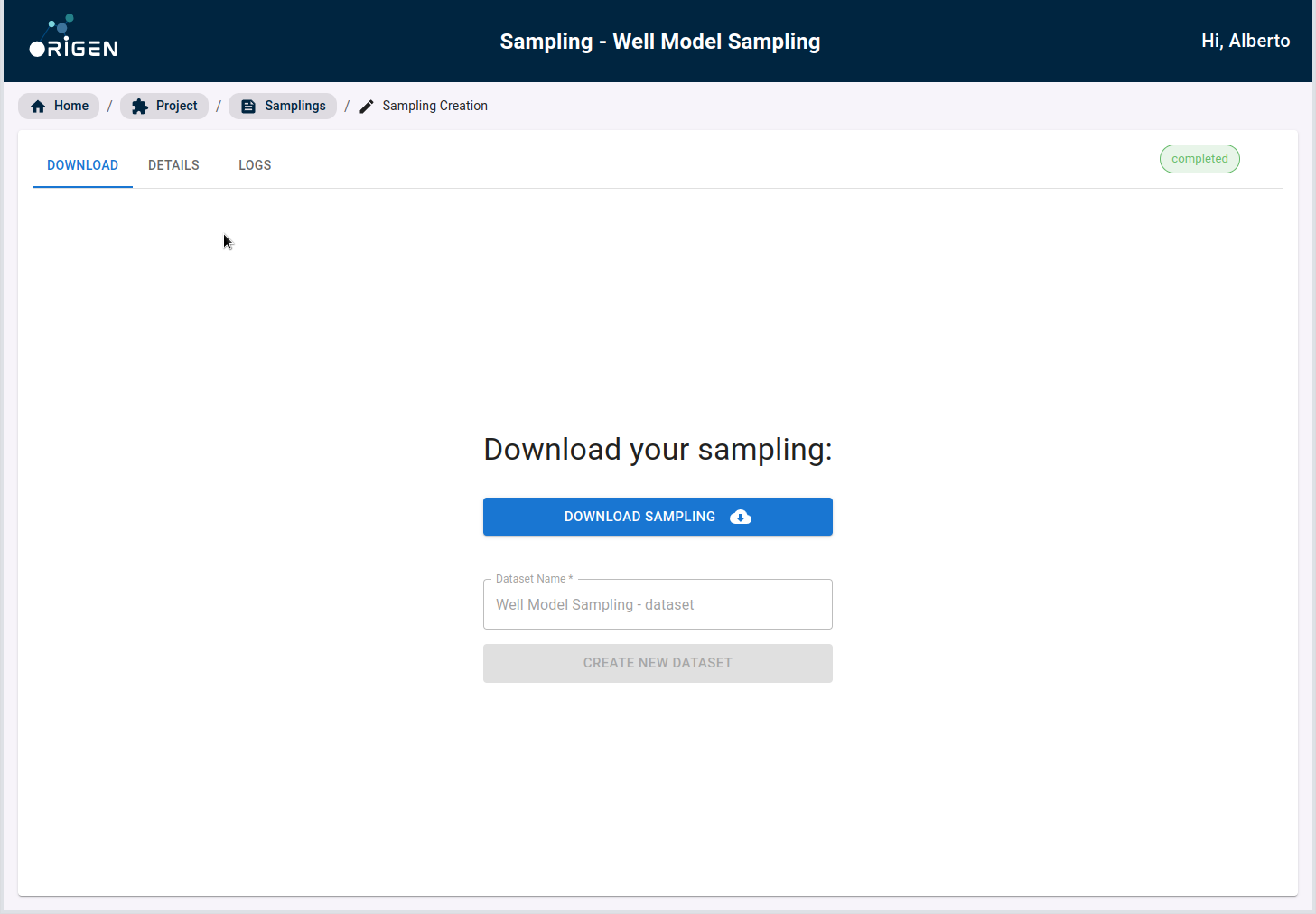
Once you download your sampling, the button to create new datasets is enabled.